
Content-Based Retrieval является динамично развивающейся областью информатики. Среди актуальных проблем - поиск речевых документов по текстовому запросу пользователей. Как найти нужный материал в коллекции аудиофайлов, не прибегая к прослушиванию каждого из них? Реально ли сделать это путем введения обычного текстового запроса?
Оказывается, да. О том, как этого достигнуть, рассказала доцент кафедры прикладной математики и информатики ВятГУ Александра Татаринова:
Мы исходили из гипотезы, согласно которой поиск должен производиться не конкретно по распознанному тексту, а путем его преобразования в фонемное представление.
Молодому ученому вместе с научным руководителем Дмитрием Прозоровым, профессором кафедры радиоэлектронных средств ВятГУ, удалось добиться поставленной цели: были предложены метод поиска и алгоритм фонемного транскрибирования на основе многосвязных цепей Маркова. Теперь пользователь, имеющий некую коллекцию аудиофайлов, может сделать запрос путем ввода текста, а система переведет его в фонемное представление, обеспечивая максимальную точность поиска.
Проведенное исследование легло в основу диссертационной работы Александры Татариновой, а последние результаты нашли отражение в статье «Comparison Of Grapheme-to-Phoneme Conversions For Spoken Document Retrieval», вошедшей в сборник материалов конференции IEEE EWDTS 2019.
Разработанные ученым ВятГУ метод и алгоритм могут использоваться для создания систем, нацеленных на получение актуальных для коммерческих компаний и государственных учреждений сведений: от жалоб потребителей товаров и услуг до получения данных о разглашении конфиденциальной информации.
Сегодня Александра Татаринова также активно занимается исследованиями в области Grammatical Error Correction. Это, в первую очередь, устранение нарушений грамматической связи между словами в предложениях, для решения которой могут быть использованы глубокие нейронные сети.
По сути мы должны обучить нейронную сеть находить и исправлять в предложениях несогласованность, возникшую в результате опечаток или слабого владения пользователем русским языком. Это мы делаем на основе нейронной сети с архитектурой Transformer, содержащей механизм self-attention, что позволяет лучше обучить связям между словами внутри предложения, -
пояснила А.Г. Татаринова.
Исследования, проводимые молодым ученым, полностью соответствуют мировым трендам. Важно, что эти темы находят отражение на занятиях со студентами, приобщая их к новейшим научным достижениям. Это, в частности, можно сказать о курсах «Математические модели распознавания образов» и «Компьютерное зрение», которые Александра Геннадьевна читает для обучающихся в магистратуре Института математики и информационных систем ВятГУ.
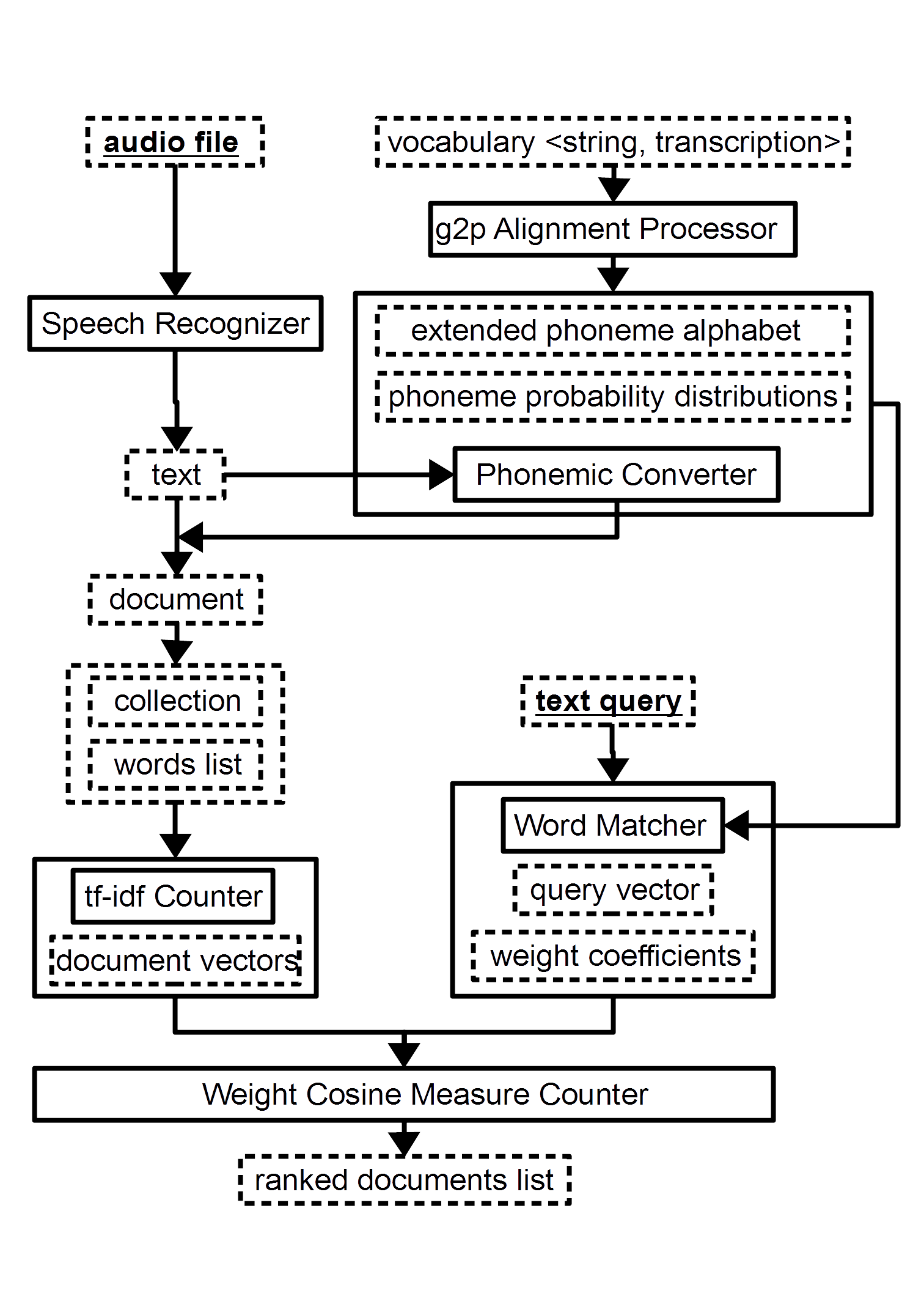
На рисунке: схема системы поиска речевых документов по текстовому запросу
{kind=link}